Match vs Find: Which One To Use in MongoDB
Last updated on 30 June 2022
MongoDB aggregation pipeline has given us the $match operator to filter out all the documents in a collection and perform aggregation operations (group, lookup, sort, etc.) on the smaller set of documents (for performance reasons). But what if you only need to fetch data, can you use $match and find interchangeably?
In this article, we will explore $match vs. find, when to use each one along with some working examples.
Here is how it is structured:
- 🗞️ $match stage introduction
- 👷♂️ Benchmarking performance ($match vs find)
- 💡 Which one to use?
- 🔮 Working examples using both operations
- 📝 Conclusion
Introduction to $match stage
Before we jump into the benchmarking and take decision on what is the right approach for reading data, let's look at some of the basic differences in both the operations.
Here are some of the things that $match stage is capable of:
- It can be used in an aggregation pipeline.
- It filters the documents in a collection against a set of conditions. Only the matched documents proceed to the next stage of the aggregation pipeline.
- It has certain restrictions.
Find operation on the other hand, is completely opposite. It can be used independently, outside of an aggregation pipeline and it has no such restrictions as the $match stage has.
Benchmarking performance
There are a lot discussion in the community regarding the speed differences of match stage vs a simple find operation for fetching data.
Let's try to perform both of these operations on a same dataset to see for ourselves.
We have a sample dataset hosted on the free tier of Atlas Cloud for the purpose of this comparison. We will execute match and find on the same collection (and thus, same indexes). Here's how a document of our sample shipwrecks collection looks like:
Sample shipwrecks document
1{2 "_id": {3 "$oid": "578f6fa2df35c7fbdbaed8c4"4 },5 "recrd": "",6 "vesslterms": "",7 "feature_type": "Wrecks - Visible",8 "chart": "US,U1,graph,DNC H1409860",9 "latdec": {10 "$numberDouble": "9.3547792"11 },12 "londec": {13 "$numberDouble": "-79.9081268"14 },15 "gp_quality": "",16 "depth": {17 "$numberInt": "0"18 },19 "sounding_type": "",20 "history": "",21 "quasou": "",22 "watlev": "always dry",23 "coordinates": [{24 "$numberDouble": "-79.9081268"25 }, {26 "$numberDouble": "9.3547792"27 }]28}
Lastly, we have created an index on the feature_type field:

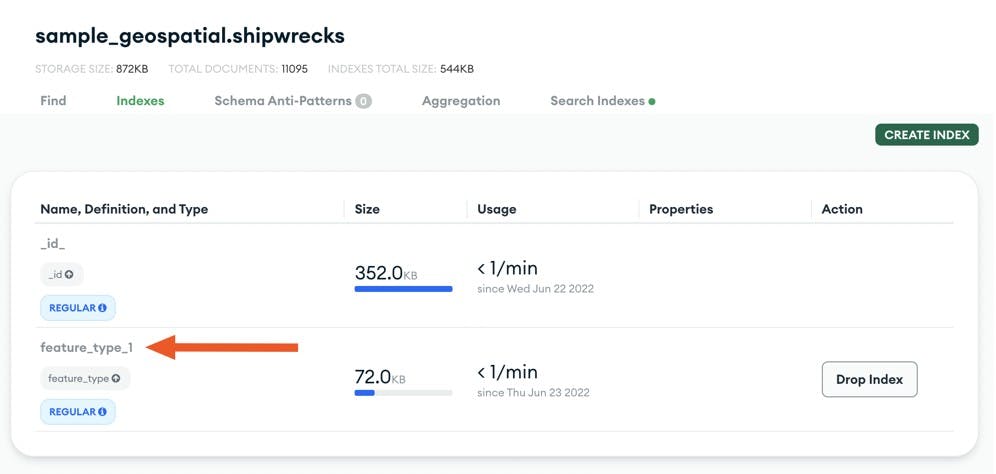
Query plan in MongoDB
To execute a query the most efficient way, MongoDB creates a query plan for each query that runs. There are often multiple ways to execute a database query, which is why MongoDB only proceeds with the most efficient way, also known as, the winning plan.
The winning plans shows all the stages used, in a hierarchical fashion.
1"winningPlan" : {2 "stage" : <STAGE1>,3 "inputStage" : {4 "stage" : <STAGE2>,5 ...6 }7},
To look at the query plan for a MongoDB query, simply chain a .explain() at the end of the query. You can also do .explain('executionStats') if you are only interested in that. Same follows for other keys in a query planner (like serverInfo & queryPlanner).
Using find()
Let's query our shipwrecks collection for our indexed field. We'll be using MongoDB Compass here but you can use this query to perform a find operation:
1db.shipwrecks.find({2 "feature_type": "Wrecks - Visible"3}).explain();
Here is the output on Compass:


Let's understand the above output closely:
- Compass gives us this nicely formatted json output of the query planner which contains all sorts of useful information.
- Looking at the winning plan will tell us the plan (or strategy) that MongoDB found suitable for our query.
- As we know, the first stage of the winning plan is the inner most node (or leaf node) of the tree. It is
IXSCANwhich means index scan. There are other fields in theIXSCANscan which tells more about the index likeindex_name,direction,indexBounds, etc. - After index scan is performed, the second stage (parent node) is the
FETCHoperation which finally fetches the data. executionStats.executionTimeMillisgives the total execution time taken by the query.
Using $match stage
To fetch the data using the $match stage, you can run the following query:
1db.collection.aggregate([2 {3 "$match": {4 "feature_type": "Wrecks - Visible"5 }6 }7]).explain();
Again, we have run the aggregation on Compass like this:

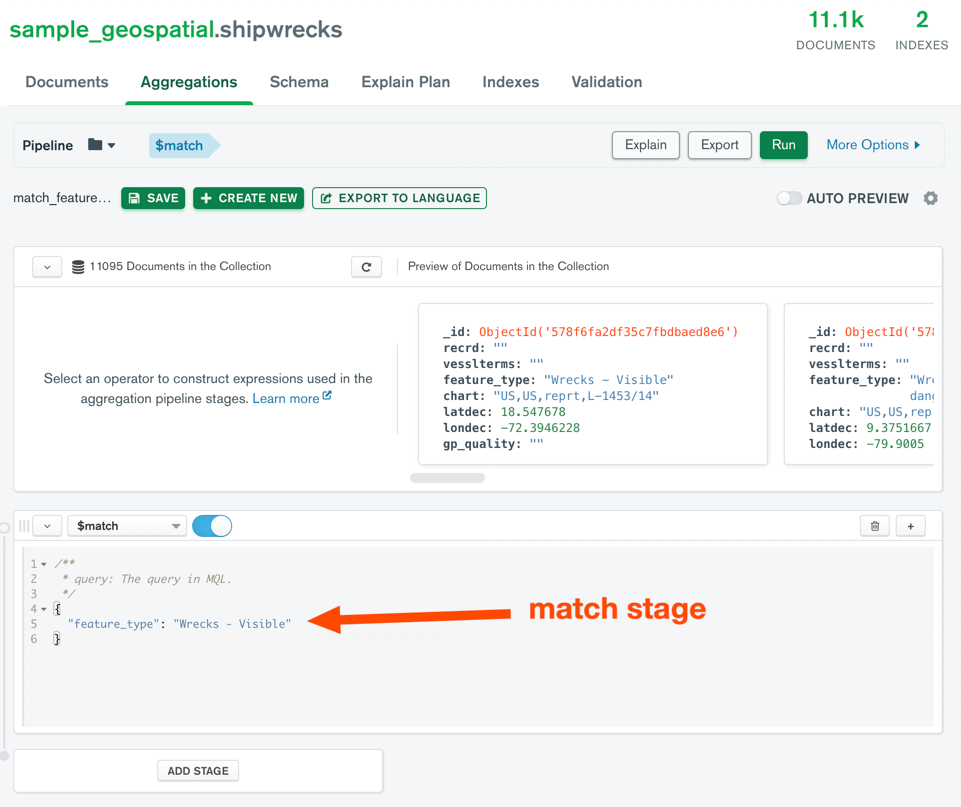
And here is the stats we get:

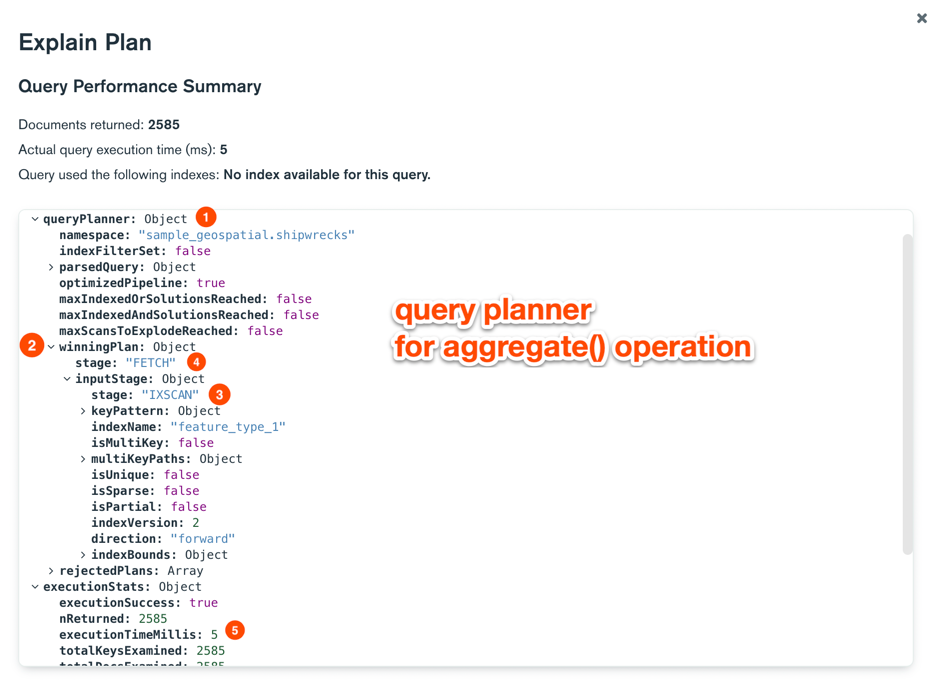
As you can see, the winning plan is exactly the same as in case of find operation. Even the execution time is close.
Which one to use?
Since there is no difference in the execution stages and the time taken for both operations, it is a personal preference in the case of a simple read operation.
But when it comes to modifying the data, find() operation fells short. This is where aggregation pipeline shines. You can do projections, group data, perform lookups, sort result, and so much more.
Even though it is not impossible to achieve the same with a find operation, it is certainly unnecessary, inconvenient, and error-prone. You'd have to build a custom in-house solution.
Don't reinvent the wheel they say.
Let's understand this with the help of an example.
Examples
Let's take a look at a few examples and see the differences in the syntax 👇
Fetching data
A simple read operation using find is done like this:
1db.collection.find({2 key: 13})
The syntax of performing the same fetch operation using $match operator in the aggregation pipeline looks like this:
1db.collection.aggregate([2 {3 "$match": {4 "key": 15 }6 }7])
I don't think there is any major difference in the syntax to make you prefer one over the other, but find operation is concise.
Counting
With find method, you can chain the .count() method to the find result:
Fetching count of matching documents
1db.collection.find({ key: 1 }).count();
Whereas in case of $match operator, you'd need another stage in the aggregation pipeline to count the items/field:
Run this to get count of matching documents
1db.collection.aggregate([2 {3 "$match": {4 "key": 15 }6 },7 {8 "$count": "key"9 }10])
While the syntax is starting to deviate, both approaches are still not largely different. You will be just fine in choosing one over the other. One can rightly argue on the better readability of the find operation here.
Fetch release years with good movie ratings
For the purpose of this example, let's suppose we have a movies collection and we want to know which years had the lowest movie rating greater than 7.
Here's the $match stage combined with the $group stage using the MongoDB aggregation pipeline:
1db.movies.aggregate([2 {3 $group: {4 _id: {5 year: "$release_year"6 },7 minRating: { $min: "$rating" }8 }9 },10 {11 "$match": {12 minRating: { $gt: 7 }13 }14 }15])
So convenient. How can we implement the same with a find operation? Let's brainstorm:
- Perform a find operation to fetch ALL the data,
- Iterate through all the entries and store the lowest movie rating for every given release year,
- Finally, iterate over the results of step #2 again to collect the final results with rating greater than 7.
As you would have observed, aggregation pipeline is very useful in complex scenarios like this. It abstract away the nuances and provides a clean & concise way of getting the right insights out of your data.
Conclusion
This was a brief explainer on the differences between the find operation and match stage. We looked at the performance (in)difference in match vs. find, understood the query plans and the use-cases for both operations.
To summarize, using $match or find() is completely dependent on your use-case. If you just want to fetch the data, find is convenient. For even slightly complex scenarios, use $match.
I hope you found the article helpful. If you feel there's anything missing or can be better explained, I would love to know your thoughts in the comments down below 🙂.
Liked the article?
If you enjoyed this article, you will like the other ones:
- Learn How to Use Group in Mongodb Aggregation Pipeline (With Exercise)
- 5 Tiny Developer Workflow Tips to Improve Your Productivity
- How to Use Project in Mongodb Aggregation Pipeline
- Introduction to TCP Connection Establishment for Software Developers
- 5 Things You Must Know About Building a Reliable Express.js Application