Better Server-Side Pagination Without Offset
Last updated on 03 August 2022
We have all created basic CRUD websites. Looking back at my personal projects, I seemed to be doing okay without pagination. Why so? Because the scope of the project was very small. So small that even fetching all the rows at once didn't feel like anything.
When working with a large dataset, pagination is a must-have. You must have noticed this at work, or in the codebase of any decently sized open source project.


In this article, we will understand why server-side pagination is better than pagination on the client-side. Why you should avoid offset, use keyset pagination, and get a better performance API when working with large datasets.
Here's how the article is structured:
- 🤔 Why server-side pagination?
- 🪜 Different ways to implement server-side pagination
- 🍽️ How server-side pagination is usually implemented
- 🐢 What is wrong with the above implementation?
- 🐇 A better approach to server-side pagination
- 🌀 You might still need offset pagination
- 📢 Conclusion
Setting up MongoDB Atlas
We'll be using the sample database on MongoDB Atlas for the purpose of this article. I have created an index on saleDate field, we will need it later:

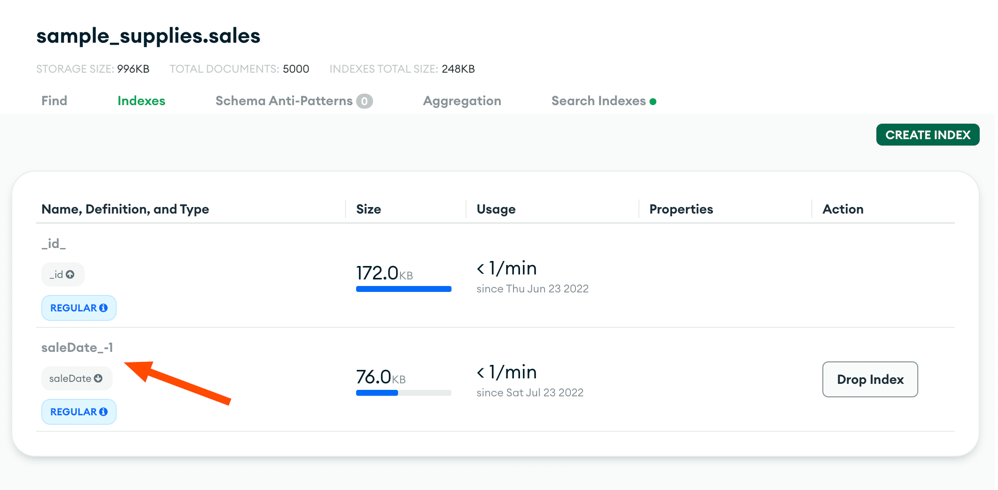
The code for the sample Expressjs application is available on Github.
Why server-side pagination?
Let's look at how client-side pagination works and understand why server-side pagination is better.
As the name suggests, client-side pagination happens on the client side. All the data gets fetched at once, and UI components show that big chunk of data in pages.
We have previously established that fetching all the rows of a table at once is never a good idea. Even though client-side pagination is near instant once you have the data, the root issue remains.
Client-side pagination is not a viable option if the dataset is large or has the potential to be. Let's move on to server-side pagination.
How to implement server-side pagination
We will look at two ways to implement pagination in your express API:
- Offset based pagination
- Cursor based pagination or Keyset pagination
Offset based pagination involves using a combination of offset (or skip in MongoDB) and limit to fetch pieces of data.
Cursor based pagination does not use offset and instead uses a cursor or pointer to keep track of iterations and moves sequentially forward.
Using offset based pagination
Offset based pagination is intuitive and it makes sense. A perfect recipe for wide adoption. It is only innocent till the latency for fetching data is reasonable. Go bigger with your dataset and it tells a completely different story.
Here's the essence of how to perform server-side pagination using offset & limit:
1db.Item.find()2 .offset(offsetValue)3 .limit(limitValue);
- The above query first fetches
offset + limitnumber of documents. - It skips over the
offsetValuedocuments. - Returns the documents from
offsetValue + 1tilloffsetValue + limitValue.
What is wrong with the above implementation?
The reason for the offset-based approach to be significantly slow is because it fetches more data than it needs.
When working with offset based pagination, it fetches all the rows up till the desired row.
The database will fetch offset + limit documents even when you only need limit documents after the offset.
Here's the explain output for fetching the last 20 documents from a collection containing 5000 in total.

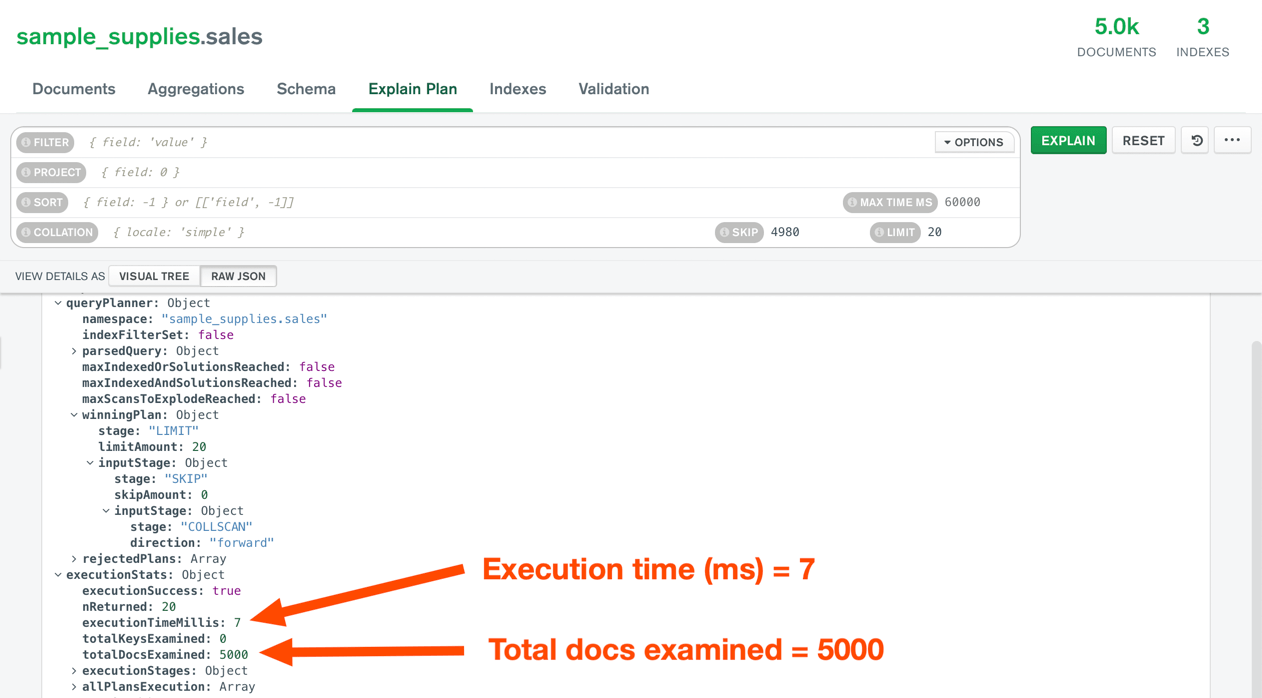
As you can see, total docs examined is 5000.
This becomes worse with the increasing number of the documents. Your users will think your website is probably broken and they will bounce.
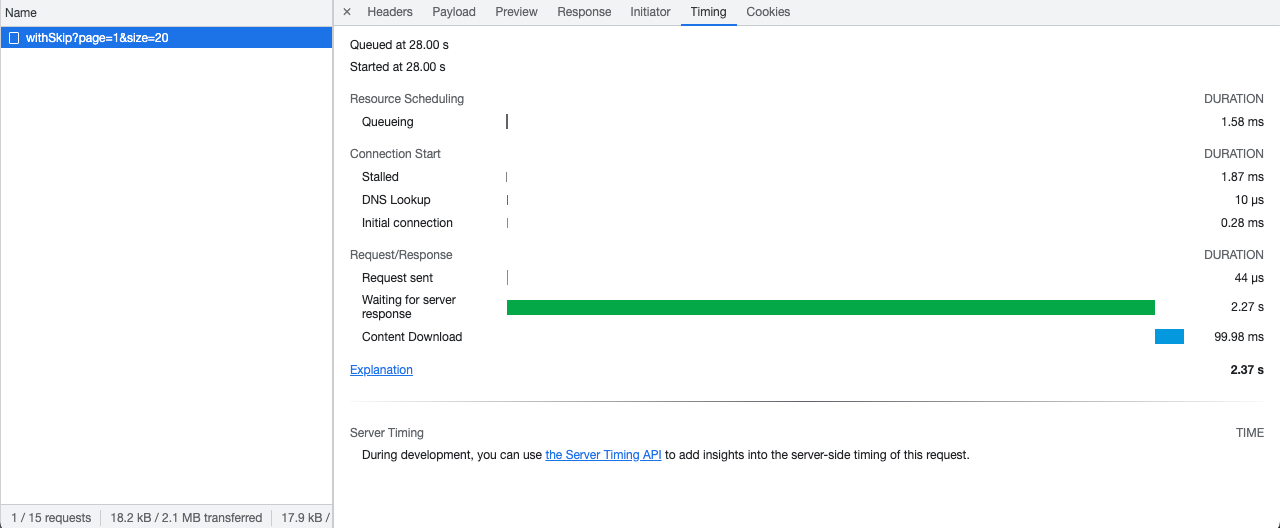
Here's how much time it took in fetching only 20 documents from the collection containing 5000 documents in total:

A better approach to server-side pagination
We've established that using offset is bad for pagination in terms of performance. Let's look at the alternative.
We need a way to process data in a specific order, and have a cursor to store a point of reference when fetching paginated data. We need a way to seek data.
To ensure we have the data in a specific and predictable order, we can sort the data based on any column. The column must store unique values for the sort to be consistent. Hence, timestamp is usually a good column to target. Never sort on names, city, or any other field which may have duplicate values.
Once sorted, it is just a matter of fetching the data in chunk of X (let's say 20) and store the timestamp of last document you fetched. It will be used to fetch the second page using the WHERE clause.
Let's take a look at the code.
Fetching sales data using keyset pagination lines={5
1router.get("/withoutSkip", async (req, res) => {2 const maxTriggerDate = req.query.date;34 const sales = await Sales.find(5 { saleDate: { $lt: maxTriggerDate } },6 {},7 { limit: 20 }8 );9 res.json({10 data: sales,11 error: false,12 message: "Sales data fetched successfully",13 totalPages: 1,14 });15});
Looking at the explain results, it is obvious why this approach is faster:

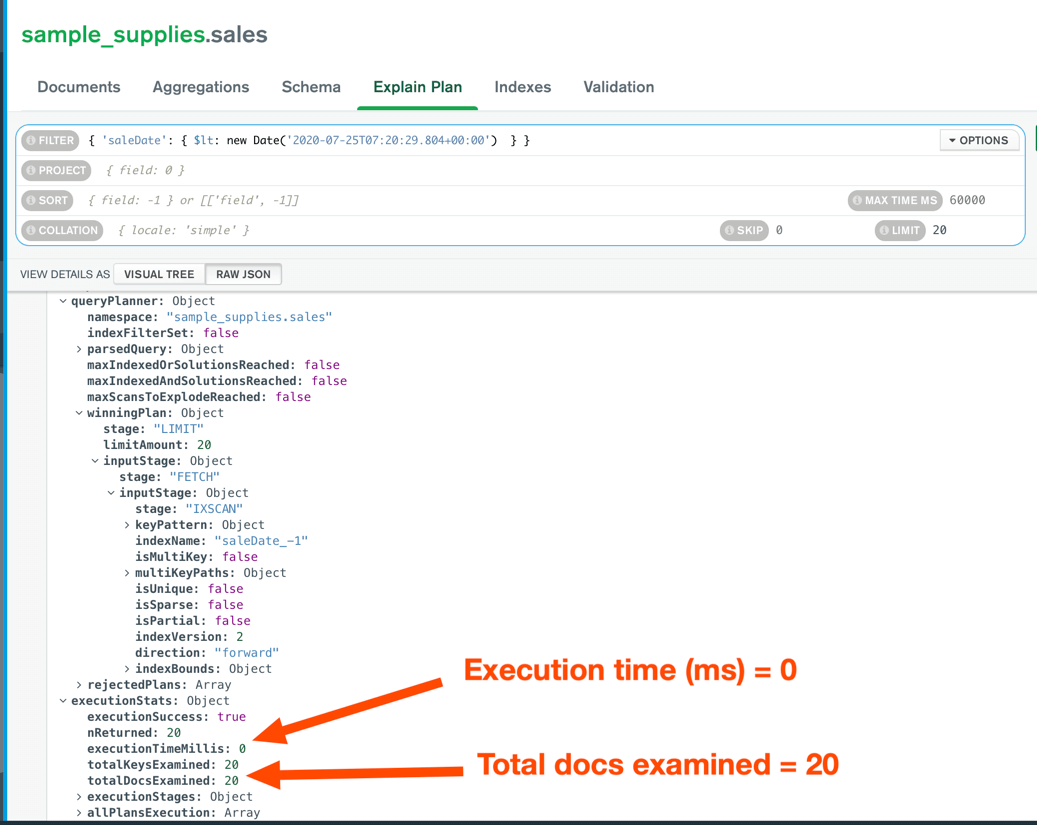
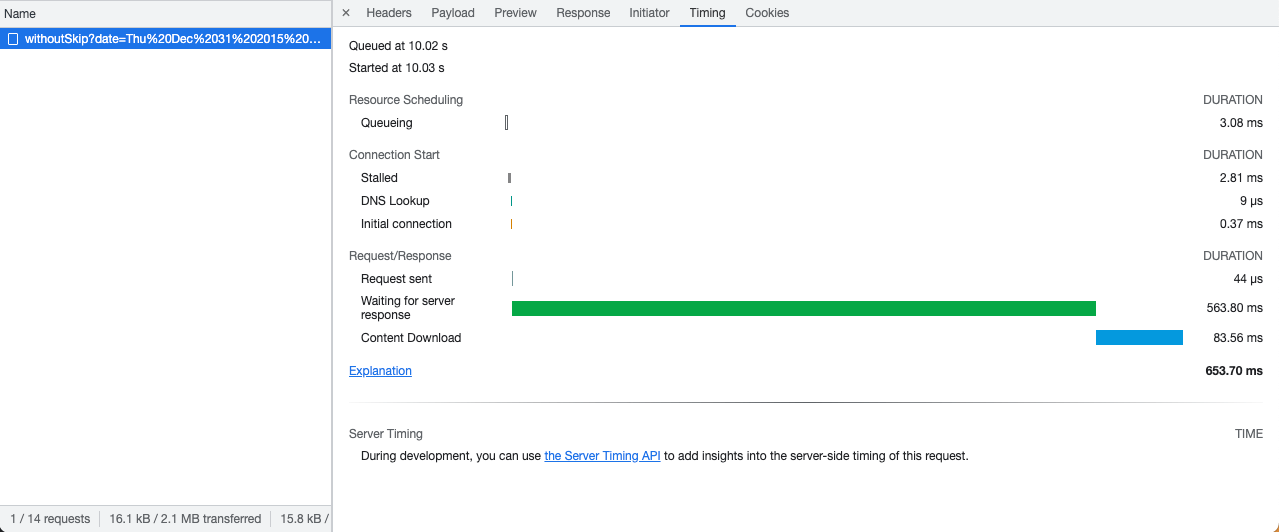
Unsurprisingly, here's how much time it took for our Expressjs API to return 20 documents from the same collection:

You might still need offset pagination
While the cursor-based implementation wins the performance battle, using offset-based pagination doesn't hurt if you are dealing with a relatively small amount of data (eg. weekend projects).
And if you have ever tried implementing both, you would know that offset-based pagination is way more intuitive and straightforward to implement. Cursors, on the other hand, can be a bit trickier.
Even though offset pagination has other flaws as well (eg. the risk of skipping unread documents if a delete happens while you're fetching), it is practically rare if your project doesn't have many active users.
Now that you know the trade-offs, you can take the decision based on your use case.
Conclusion
This wraps up our journey to server-side keyset pagination. In this article, we learned what it means to paginate data, why you should use server-side pagination, and almost always avoid offset.
You should never fetch a large amount of data from the backend. I hope you got clarity on the approach and the implementation.
The sample project used in the article is available here.
If you want to explore further, I'd highly recommend reading this article.
Feel free to reach out in the comments if you have any queries or want to discuss the implementation.